Exploring Graph Database Versioning Approaches
Update (2026): the thinking in this post is now carried forward in Minigraf
Building on my previous post, where I emphasize the need for versioned graph databases, I explore a few of the possible approaches to designing one. This is not a ground-up approach that delves into the design of the database engine itself, but rather an overlay approach that can let us run version control atop any standard graph database.
A Naive Approach
Think of a historical key-value store - one where the history of values against every key is retained, and retrieved using a composite of the key and a revision number (absolute or relative). Optionally, to get the current value of a key, we may omit the revision number. This is one of the simplest conceptual forms of a historical database. Since many real world graph databases are built on top of an underlying key-value store (ArangoDB, JanusGraph, DataStax Enterprise Graph), we will try to use our historical key-value store to see if it gives our graph database some degree of history retention.
We can naively concoct a graph representation on this database by storing documents as key-value pairs - keys being the unique document ids and values being their respective attribute-value pairs or property lists. For the sake of this thought experiment, we will not bother with how the connections are internally represented, i.e. whether source and destination node ids are stored as edge attributes, or incoming and outgoing edge lists are stored as node attributes, or some other fancy scheme (In real-life graph databases, this is dictated by the design the underlying implementation).
The Historical KV Store - A Closer Look
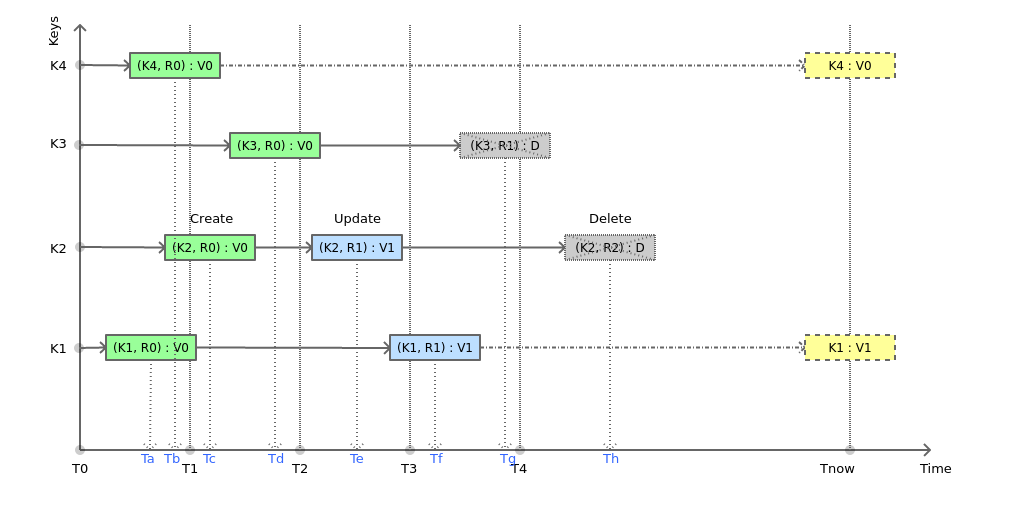
Figure 1: Evolution of stored data over time in the historical KV store
The figure above shows what the contents of this key-value store might look like for a few sample key-value pairs. Every write operation (create/update/delete) for a given KV pair is associated with a revision number and a timestamp. The latest value for a key is always immediately available using a simple key lookup. This can happen in O(1) for an in-memory store. This is depicted in the figure by projecting the latest values of existing pairs onto the line Tnow. However, when we want to find out the state of the database at some point of time in the past, things get a little more complicated. The table below shows the values of all the keys depicted in the figure, at different times.
Table 1: Projection of historical values at different times | |||||
T1 | T2 | T3 | T4 | Tnow | |
|---|---|---|---|---|---|
K1 | V0 @ (R0, Ta) | V0 @ (R0, Ta) | V0 @ (R0, Ta) | V1 @ (R1, Tf) | V1 |
K2 | -- | V0 @ (R0, Tc) | V1 @ (R1, Te) | V1 @ (R1, Te) | D @ (R2, Th) |
K3 | -- | V0 @ (R0, Td) | V0 @ (R0, Td) | D @ (R1, Tg) | D @ (R1, Tg) |
K4 | V0 @ (R0, Tb) | V0 @ (R0, Tb) | V0 @ (R0, Tb) | V0 @ (R0, Tb) | V0 |
Temporal Queries
This table was easy to build from the visual depiction in Figure 1. But how does our historical KV store figure out the state of the DB at, say time T3? Here's what we have to work with:
Revision numbers can be relatively referenced (similar to Git), so we can assume these to be integer values starting with 0. Positive numbers reflect revisions w.r.t. the beginning of revision history (
R0) and negative numbers w.r.t to the end (Rlatest).Since the database allows both key-only lookups (for latest revisions) and key+revision lookups, we can assume that it internally maintains a 2-field hash index
(key, revision), keeping the 2nd level sorted in reverse order of the revision number (to facilitate retrieving the latest version for key-only lookups).
Therefore, to find the value of, say, K2 at time T3, we need to perform the following steps:
Determine if
T3is closer toT0orTnow. Based on this, we will start from the oldest or the newest revision ofK2respectively.If
T3is closer toT0. i. Setnto0. ii. LookupK2 @ Rnand note its timestampT. iii. IfT > T3then returnK2 @ R(n-1)(Ifn = 0then returnnull). iv. Else increasenby1and go to step (ii).Else if
T3is closer toTnow. i. GetK2 @ Tnow. Note the revision number and assign toN. Note its timestampT. ii. SetntoN. iii. IfT < T3then returnK2 @ Rn. iv. Else decreasenby1. v. GetK2 @ Rn, note its timestampTand go to step (iii).
This is evidently far more complex than a simple key or key+revision lookup, and not in O(1) anymore. It is now O(N(K)) where N(K) is the number of revisions for key K. This greatly inefficient lookup can be speeded up drastically by additionally maintaining a 2-field skiplist (see below) index (key, timestamp), keeping the 2nd level sorted in reverse chronological order. This is still at best an O(log(N(K))) operation.
A skiplist index supports both equality and range queries. So we can ask it to return all values for key =
Kand timestamp <T.
Conclusion
We see that while this design provides a history of every individual document out of the box, and the history can be queried by revision number or point-in-time,
It does not readily expose the the structure of the graph as a whole (or subgraphs, or
k-hopneighborhoods - all of which might be of interest to a network analyst.),Fetching a past state of the graph is more expensive than fetching its current state (this should be an acceptable trade-off for most OLTP scenarios),
The revision-number based historical KV store does not offer any intrinsic benefits for time-based lookups, and
There is potential for a lot of storage and write-bandwidth overhead when storing multiple versions of large documents where each version only updates a small portion of a document, since it results in redundant storage.
We see that this approach has several drawbacks which make it unsuitable for an efficient historical graph data store. We will explore other, hopefully better approaches in future posts.
