Exploring Temporality in Databases
Approaches to version-controlling your data - a conceptual overview.
Update (2026): the thinking in this post is now carried forward in Minigraf
Getting Started with Time
Time is of some importance to humans. The best scientific minds have yet to unravel all its mysteries. Even its definition is a recurring subject of debate. Yet, we all innately have a sense of what time is. It would be hard to discuss any subject at length without reference to the aspect of time. It is a fundamental component of all knowledge. In fact, it is a fundamental component of language itself - try constructing a contextually self-contained sentence without a single verb.
It is evident that in all accessories we've devised to store and dispense knowledge, time has always been a deeply integrated, first-class citizen. Databases are no exception. It is not uncommon to see a time-like field associated with a fact stored in a database.
Facts That Change with Time
For the purpose of this post, we can think of timestamped facts as being of one of two kinds - event and state.
An event is a record in the database of something that occurred in the real world. The actual event, once it has occurred, can no longer be altered (unless you're Dr. Who). However, its database record, although ideally immutable, may sometimes need to be updated or superseded (to correct an error in data entry, for example).
A state, on the other hand, represents a portion of our overall knowledge of an object or entity of interest. For example, it could be a person's employment record, their address, or the location of a parcel in transit. State records in a database are generally mutable.
Note: An important distinction must be made between an entity's identity and its state. The entity itself is usually referenced with an immutable identifier. It is only the stateful attributes associated with the entity that are mutable. There could be exceptions, but they are more often due to poor schema design than to constraints imposed by the real world.
Note: The most common relation between events and state is one of causality. An event is an agent that causes a mutation in state. For example, when a parcel in transit reaches a particular hub, its location on record is updated. In this case, the event is the parcel having reached the hub, and the state is its location (old location before event, new location after). The event (parcel reached hub) causes the state (location) to get updated.
Tracking Mutations
Having established that both events and state have a temporal aspect to them, we next explore how their mutations over time can be tracked. Hereon, the term temporal field refers to a time-like field that can be used to identify versions of an individual fact. A temporal dimension is the domain of a temporal field, i.e. the ordered set of valid values for that field.
For immutable events, temporality does not actually come into play. A timestamp field to record the time of occurrence may be present, but since this record is never altered, the event only ever has a single version, and hence the timestamp may be treated like any other non-temporal field.
For mutable events and for state, change can be fundamentally recorded in one of two ways:
i. Overwrite the previous record with new data - this is easy to implement, but we lose the older version. The older version may be retrieved from the DB replication logs (if we diligently save them), but it is a tedious, time-consuming process.
ii. Append the new data to the DB - supersede the old data related to an entity or event with new (timestamped) data, but preserve the old data such that it is easily accessible. This has the added overhead of providing a mechanism to retrieve the right version of the fact, based on a timestamp and a non-temporal entity/event identifier.
It is the latter case (timestamped revisions using appended updates) that is the subject of interest in this post. This is obviously much harder to implement than simple overwriting, especially if we have to design the versioning layer in the DB schema ourselves (as opposed to the DB internally tracking versions for us), but it does give us time-traveling superpowers.
Approaches to Time-Based Fact-Versioning
Let us take a moment to try and visualize the two different approaches to storing and updating mutable facts that we've seen so far.
Case: 0 Temporal Dimensions
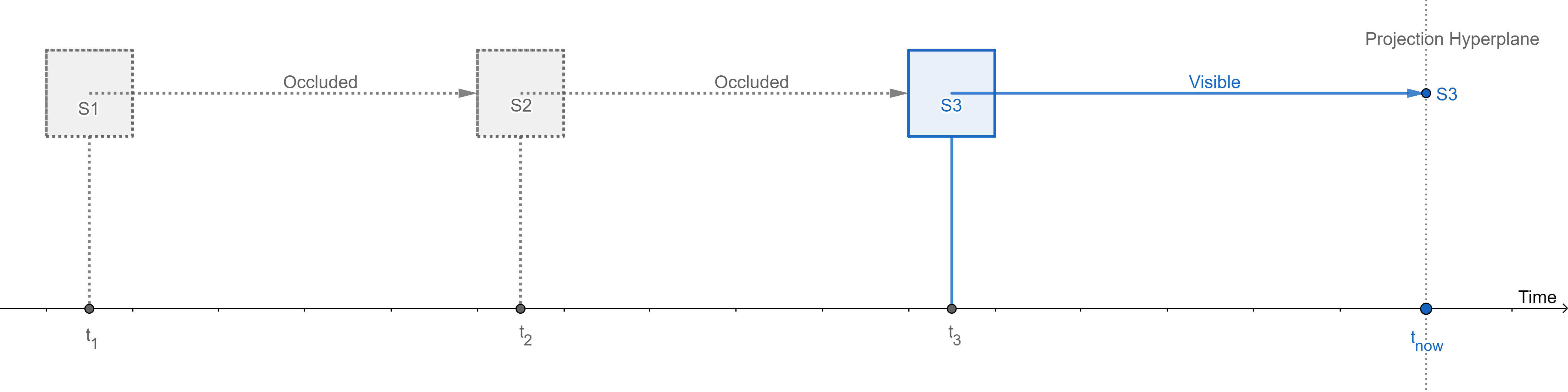
Figure 1: Mutation history with 0 temporal dimensions.
Figure 1 is an abstract representation of what happens in a database where old data for an entity (row/document/key) is always overwritten by new data. The diagram shows the evolution of state through time of a single entity. On the timeline, each state that this entity has even been in is indicated by a box labelled S₁, S₂, S₃, etc.
Even though from our perspective we can see historic states in the diagram, the database only gets to see whatever is projected on the line labelled Projection Hyperplane, i.e., the latest recorded state. This imaginary hyperplane always crosses the timeline through the present instant, and hence acts as a marker of the present moment. Past states are inaccessible to the database. This is depicted in the figure by the projections of older states getting occluded by subsequent newer states.
We shall see shortly why this abstract representation is a useful tool in understanding temporality in databases.
Case: 1 Temporal Dimension
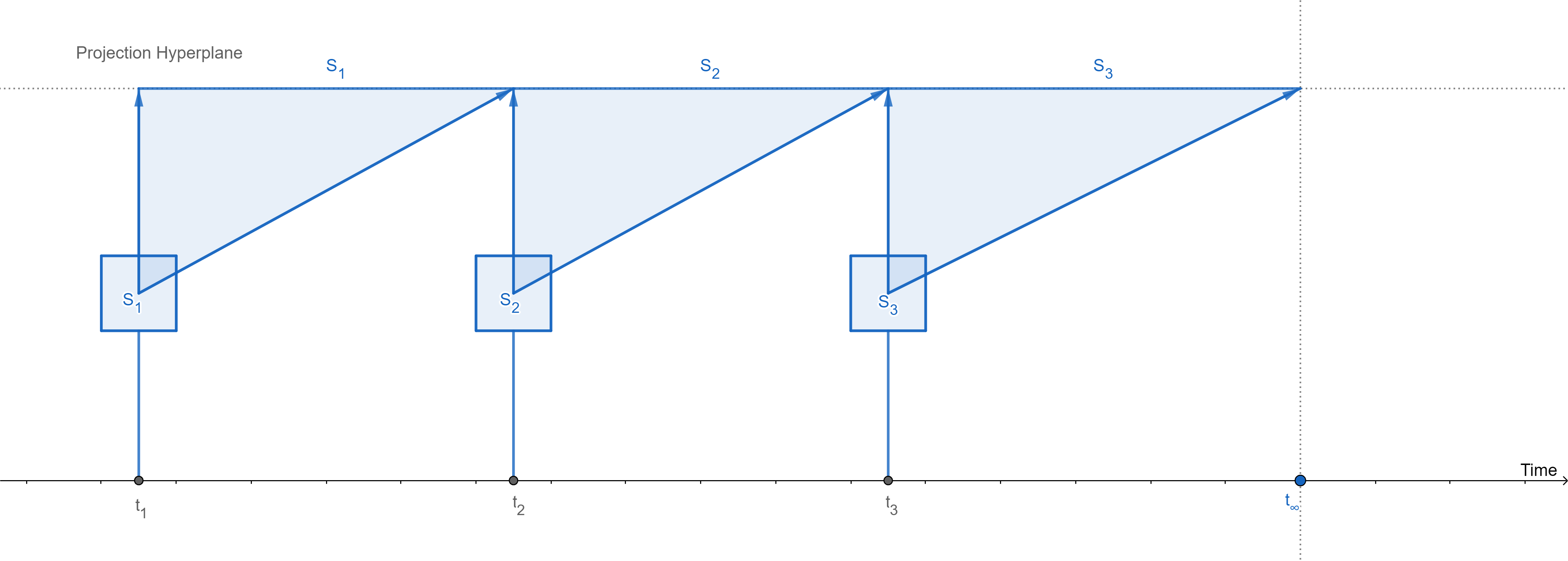
Figure 2: Mutation history with 1 temporal dimension.
Figure 2 demonstrates the case where the database updates data such that it still retains the old versions. This is represented in the figure by reorienting the Projection Hyperplane so that it is now parallel to the time axis. Due to this, older states can now project their presence onto the hyperplane without occlusion. The last known state gets to project its presence to ∞ along the temporal dimension. ∞ is represented by a dotted line crossing the time axis.
A note on implementation specifics: The visible temporal axis may be implemented as an internal database feature, or as part of explicit schema design (visible to the application layer), or as schema-transparent middleware residing in the persistence layer. In all cases, the concepts explored in this post remain the same.
Case: 2 Temporal Dimensions
An interesting property of our representational model is that it is not constrained to just one temporal field or temporal dimension. By simply adding another temporal dimension to the diagram, (and to the hyperplane), we can now track object revisions using two temporal fields instead of one. We will shortly see whether this makes any sense in a real-world context, but for now, Figure 3 presents an example of a bi-temporal projection.
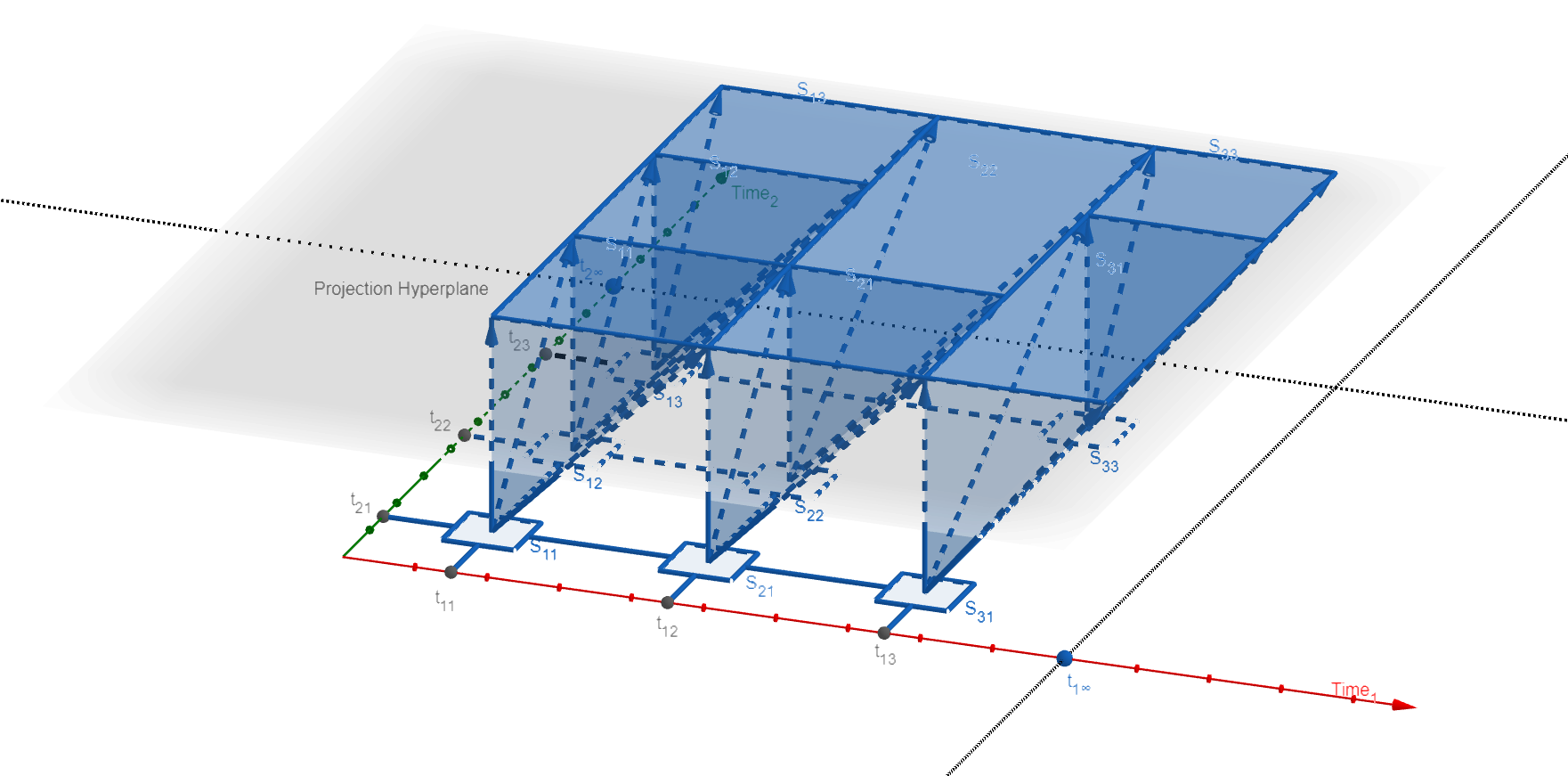
Figure 3: Mutation history with 2 temporal dimensions. For an interactive, 3D version (where you get to rotate/zoom the drawing to see it from different angles), visit https://www.geogebra.org/m/ey3sky2s.
Here, the states S₁₁,S₁₂, S₂₁, S₃₁, etc. all represent doubly-timestamped historic states of the same entity. The two temporal dimensions - Time₁ and Time₂ are laid orthogonal to each other as coordinate axes. The Projection Hyperplane is now a 2-dimensional plane hovering above the bi-temporal coordinate plane.
Each state gets to project its presence onto the Projection Hyperplane, bounded below by the timestamps of its creation, and above by the timestamps of its respective successors along each temporal dimension. The last known states on each dimension get to project their presence to ∞ along that dimension. ∞ is represented by a dotted line crossing each axis.
Note: The boxes on the bi-temporal coordinate plane, representing states at different tuples from the pair of temporal dimensions, would rarely be arranged in a perfectly aligned grid. In reality, they would be more likely scattered around seemingly haphazardly. The example in Figure 3 has adopted a less chaotic arrangement to try and simplify a rather complex diagram.
Putting it All Together
We will now explore how these representational state plots map to data in the real world. For up to two time dimensions, the ideal mappings have already been extensively researched and widely adopted, and I will just reiterate here, the conventions already in use:
A transaction time dimension consists of values from a temporal field that tracks the actual time of recording a fact. This is the point of time in the real world when the fact was recorded into the database, and is often auto-filled by the database itself. This field (along with the associated state or event data) is best kept immutable to maintain the sanctity of the system of record.
It represents what was known to the system at the time of record, or the truth, as it was best known at the time of record. It is impossible for fact versions stored along the transaction time dimension to be placed chronologically out of order. This is because they are ordered by their insertion timestamps.
A valid time dimension consists of values from a temporal field that tracks the effective contextual time of a fact, as it was known at the time of record. This is perhaps better explained by a few examples:
i. If an employee joined an organization on the 5th of June, 2020, but their employment record was preemptively created on 3rd June 2020, then the former is a valid time field and the latter is a transaction time field. This is an instance of recording before the fact.
ii. If a parcel got delivered to a customer at 12 PM, but the system was updated later at 2 PM to mark the delivery, then the former is the valid time and the latter is the transaction time. This is an instance of recording after the fact.
iii. If a user places an order on an e-commerce portal, then the time of recording the order is itself considered to be the effective time of placing the order. In this case, the transaction time and valid time are always in sync. For cases like this, a bi-temporal representation can gracefully degenerate to a uni-temporal representation. In this post, we will refer to them as actual-time systems.
A valid time field (and its associated state or event data) is generally kept mutable, and is often updated to correct erroneous data entries or to consolidate conflicting inputs from multiple systems. Fact versions stored along the valid time dimension may arrive preemptively, retroactively, or chronologically out of order w.r.t. each other.
An Example
When working with the two most commonly used temporal dimensions described above, certain interesting observations can be made.
Let us work with an example to help us understand better. Consider a flight booking system. Typically, for a given flight, the price changes over time - you get a different price depending on when you book. There are usually a lot of other factors affecting price (nowadays, almost in real time), but for this example, let us keep things simple by having the price change on a daily basis.
Now, for a given flight, the following attributes would be required at the minimum:
Flight number,
Flight date,
Booking date,
Price
Note: This example provides another interesting insight - that not every date field in an entity can or should be treated as temporal. For instance, in our example, the flight's "flight date" can actually be considered to be part of its immutable identifier. Together with the flight number, it forms a complete and unique identifier.
In our example, the booking date acts as the valid time dimension, since the price point (mutable state) goes in and out of validity based on the booking date. The time of record must invariably serve as the transaction time dimension for any sane use case.
Any system that stores this flight information would have to record some or all of the above fields for each flight, along with a explicit or implicit time of record. In principle, something like the following has to be recorded:
Table 1: A tabular representation of versioned flight data | |||
Record Time | Booking Date | Price | |
T₁ | D₁ | P₁ | |
T₂ | D₂ | P₂ | |
T₃ | D₁ | P₃ | |
T₄ | D₂ | P₄ |
However, as we shall see, the actual mechanism (and therefore capabilities) of storage and retrieval vary from DB to DB (or schema to schema), depending on whether it is uni-temporal w/ transaction time, uni-temporal w/ valid time, or bi-temporal.
Note: If you've gone through some of the literature referenced here or elsewhere on temporal dimensions in databases, you will have observed that both transaction time and valid time fields are marked using a pair of start time and end time values. This is implicitly handled in our example by marking only the start times explicitly, and assuming the end times either coincide with the start time of the next version or stretch to ∞.
Transaction Time Database
A transaction time database is an immutable system of versioning facts. A fact version, once stored in such a database, is indelible for the lifetime of the system. In our example, both price and booking date are essential attributes of a flight, and so this database must store them both (along with a record date).
However, the fact that it is a uni-temporal, transaction time database means that the "booking date" field is not available for use as a filter for the temporal version selection process. This could be due to the way it encodes its data for storage (storing deltas between versions instead of fully built state objects, for example).
Table 2: Versioned flight data in a transaction time database | ||
Record Time | State | |
T₁ | Booking Date: D₁, Price: P₁ | |
T₂ | Booking Date: D₂, Price: P₂ | |
T₃ | Booking Date: D₁, Price: P₃ | |
T₄ | Booking Date: D₂, Price: P₄ |
In order to find the last known price for a given booking date, this system would have to scan its version record (in reverse) until it finds the first version with that booking date. This is obviously a highly inefficient system for this use case.
A transaction time-based uni-temporal system is usually only useful in actual-time (as defined above) cases where the transaction time dimension doubles as the valid time dimension. An example would be the booking management sub-system for an airline, since a booking, once made, is processed in actual time (i.e., neither preemptively nor retroactively) for the span of its active lifecycle (booked -> minor changes like seat allocation, meals, etc. -> check-in -> security -> boarding -> destination).
So, although a transaction time database is useless for serving a catalog, it works just fine for live order management.
Valid Time Database
A valid time database is a mutable system of versioning facts. A fact version stored here (along with its valid timestamp) may be altered whenever new knowledge of the truth surfaces, and differs from the existing record. In our example, since the booking date is the valid time dimension, the state stored against a particular booking date can be modified in-place.
By doing so, however we lose the older price information that was known for that state. In order to find the last known price for a booking date, a simple filter on the booking date field would yield the required state.
Table 3: Versioned flight data in a valid time database | ||
Booking Date | State | |
|
| |
|
| |
D₁ | Record Time: T₃, Price: P₃ | |
D₂ | Record Time: T₄, Price: P₄ |
Bi-Temporal Database
Finally, a bi-temporal database would have access to both "record time" and "booking date" to filter on, during its version search phase. On such a database, we can ask questions like - "What was the price for booking date D₁ as it was known to the database at record time T₂? (Answer: P₁)". The data storage scheme is identical to the scheme presented in Table 1.
Appendix A: Beyond Bi-Temporal
Continuing with our projection-based representation model, we note that we needn't stop at just two dimensions. In fact this model can be extended to an arbitrary number of dimensions, and it is possible to design a database capable of storing and querying facts with n temporal dimensions. However, beyond two dimensions, the semantic mappings quickly turn murky.
This Wikipedia article speaks of tri-temporal databases (with the 3rd temporal dimension being decision time), but the semantics of >2 dimensions seem to remain unclear, while also adding to our cognitive load. Even Snodgrass, et al, in their 1985 ACM SIGMOID paper, limited themselves to just the two dimensions discussed above, with every other time-like field being relegated to the category of user-defined time (a polite way of saying "none of the DB's temporal business").
I think one way of understanding multiple temporal dimensions is to imagine each dimension as the transaction time of some system - the first being the transaction time of the database itself, the second, third.. and so on being transaction times of external systems (including non-computer systems, such as record books, meeting minutes, journals, diaries, etc.) through which the data has traveled to reach our database, and the final being the valid time dimension, i.e. the transaction time of the real world itself, also known as the clock time or wall time. Fact versions along all but the 1st dimension should be mutable.
Disclaimer: I have not put this scheme to test. It is just a hypothesis that may or may not yield usable designs.
Appendix B: Parallel/Branching Realities
Since we're discussing version control for data, it is natural to draw parallels with file-based version control, and ask how branching fits into the scheme. My take is that all the dimensions and fact versions taken together represent one version of reality. To spawn an alternate reality is to hatch a whole new set of n dimensions and start recording fact versions from scratch there. In this grand scheme of things, a branch is nothing but a child reality that has been pre-populated with data from a parent reality.
